At Vayu, we are building a robotics foundation model to power mobile robots at scale. Training a foundation model for mobility requires collecting large amounts of data across diverse scenarios, embodiments and operational domains. However, collecting such a dataset, especially one with sufficient amounts of interesting corner cases in the real world, can be costly and unsafe. While large language models have benefited from the abundance of text data that is easily accessible through the internet, robotics foundation models do not have a natural source of abundant multimodal data, i.e., data containing multiple time-synchronized cameras, inertial measurements and goals. Therefore, the data engine for building robot foundation models has been limited by the deployment of robots into the real world.
There are ways to generate data to overcome this barrier. One way to do that is by drawing samples from world models trained on collected data, such as PRISM-1, CoPilot4D, and UniSim. Vayu is working on a complementary approach to overcome this barrier – generating data from traditional graphics-based simulation engines and closing the sim-to-real gap. Decades of improvements in computer graphics have led to the development of fast and realistic game engine renderers that can generate data at scale, benefiting from modern GPU hardware. By learning a representation of simulated data that transfers to the real domain, we can turn game engines into data engines for training a foundation model for mobility. We are excited to share results for the first application of this system - a bike lane driving robot, which is being deployed on public roads today.
Advantages of a simulation-based data engine
Scale
The amount of data that can be generated scales with compute power, not with the number of deployed robots. Compute power has historically grown exponentially with time, which means that the amount of data that can be generated in simulation is likely to grow exponentially as well. Today, in our bike lane driving simulation, we generate about 500 miles of driving experience per GPU per day in diverse traffic and weather conditions, while generating multiple high resolution camera images that provide a full 360-degree surround view around the robot at a high frame rate. This means that with just 256 GPUs, we can generate about 1 million miles of experience per week.
Control
This approach offers more control over getting into and recovering from corner case scenarios compared to neural simulation, which is harder to control in precise and repeatable ways. The following are a few examples:
Supervision
A game engine-based simulation can create supervision for correct behavior using privileged information from the simulator’s state. For example, the exact positions, future trajectories and intentions of vehicles and pedestrians, state of traffic lights and locations of stopping points for traffic lights and stop signs, are all accessible. We use this information to create a teacher agent, one whose actions can be queried at any time and provide supervision for training a student agent who only has access to the sensory inputs. Privileged information is also used to procedurally create natural language explanations for the teacher's behavior, which is used for training the student model to output human understandable explanations for its actions.

Ability to accurately evaluate metrics
Metrics such as distance of closest approach to other traffic participants, distance from the lane center, gap between the target and actual speed, and frequency of traffic rule violations, can be evaluated over thousands of miles in closed-loop simulation. This is more difficult to achieve in a neural simulation as it can create action-conditioned images but not physics-based geometric ground truth, which limits the simulation’s utility towards evaluating end-to-end robot behaviors.
Creating variations of the real world
Game engine-based simulation can not only be built to reflect real-world road network topologies and city layouts, but also be combined with randomly applied augmentations to create a huge amount of diversity. For example, lane widths, building types and traffic density can be sampled randomly each time a map is used for creating a scenario.
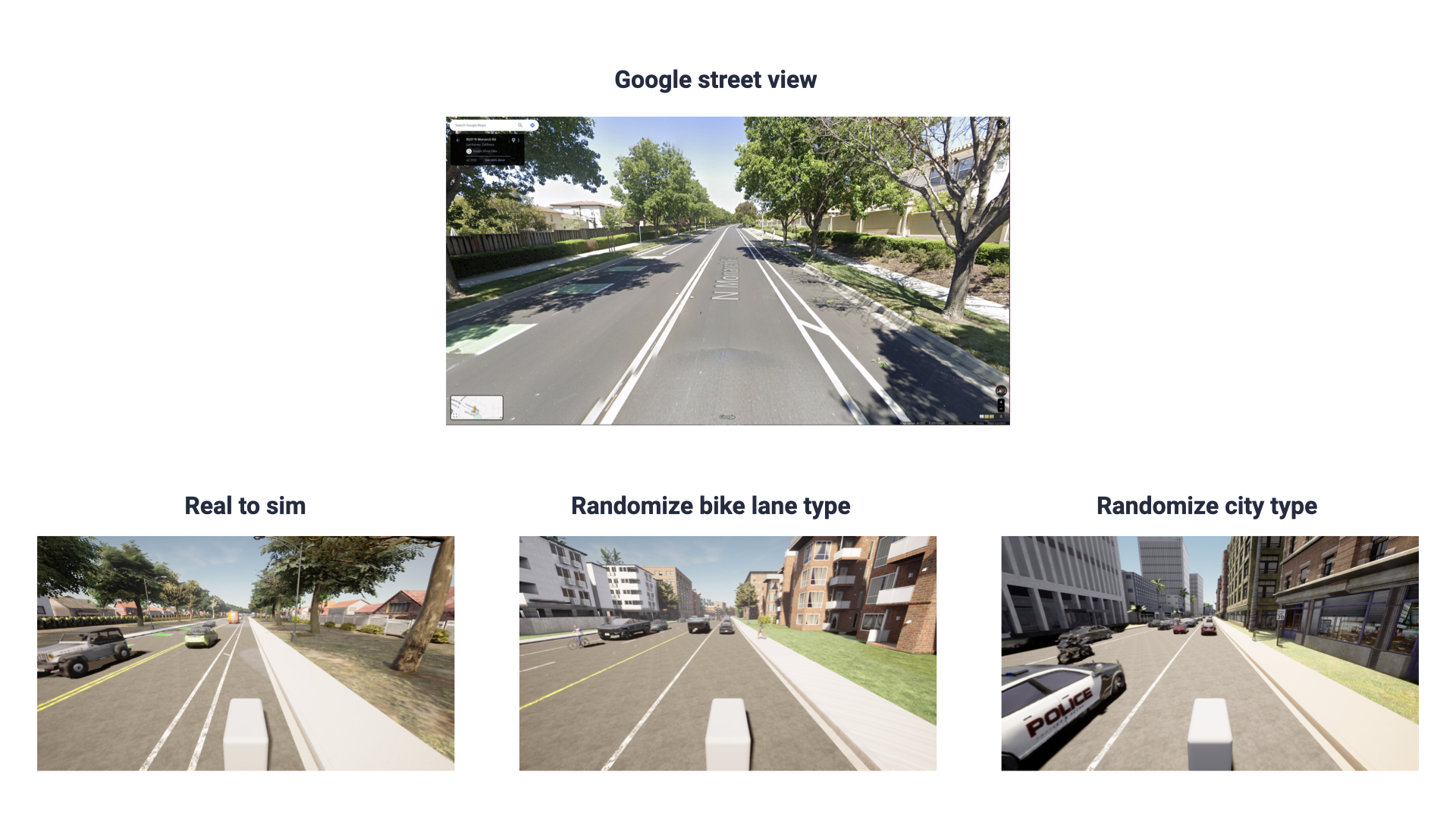
Closing the sim-to-real gap using Vision Foundation Models
Previously, game-engine based simulation has not been viewed as a viable way to produce data for training end-to-end models due to the large sim-to-real gap. However, vision foundation models, such as DinoV2, and vision-language foundation models (such as CLIP, LLAVA, CogVLM) are changing this. These models produce general-purpose image representations that perform well across multiple vision and language tasks. When encoded through these models, simulated data emulates real data, reducing the sim-to-real gap caused by rendering fidelity by a significant amount – so much so that leveraging only simulated data has become a successful reality for downstream applications. We are experiencing this same success even when the sim-to-real gap is significant. For example, when simulating data using CARLA, an open-source simulation engine that is not highly photo-realistic, we find that semantic concepts are represented very similarly between sim and real data in the DinoV2 representation space. This can be seen by training a semantic segmentation model on simulated data and testing (without any fine-tuning) on real data. As shown below, the presence of a vehicle, person, obstacle or a lane marking is similarly encoded. Depth estimation models also transfer from sim data to real data.
The ability to transfer is not limited to image-level tasks but also applies to a downstream general-purpose mobility foundation model that does path planning, along with other tasks such as language-based question answering, scene reconstruction and instruction following. The following videos show how Vayu’s mobility foundation model works in simulation and transfers to the real world without any fine tuning. The model is answering the questions
- What path should you drive on ?
- Where is the left bike lane boundary ?
- Where is the right bike lane boundary?
For each question, the model is producing a path token which is decoded to a sequence of x-y points in the robot's coordinate system.
Real versus simulation: What the robot sees
The downstream mobility foundation model has the ability to reconstruct the input scene from its latent state. We can use this to understand how the model is able to work on real data, even though it is entirely trained on simulated data. Here’s what we found: when we try to reconstruct real domain data, the resulting images have a game engine-like rendering quality, but are no different than the real data in terms of content, e.g., layout of lane markings, positions of vehicles, etc.
What does this mean? Since the scene content is preserved for reconstruction as the input data passes through the model’s internal representations, it is likely that those representations are able to generalize and transfer to real domain data. In other words, when operating in the real world, the model thinks that it is driving in a simulation environment with equivalent operating conditions. Therefore, its ability to drive correctly in simulation transfers to the real world. This does not mean that simulation and real domains are completely indistinguishable in representation space. In fact, we found that a discriminator neural network can distinguish between the two. However, the representations are similar enough that the model’s ability to operate correctly transfers over.
Scaling up
Training a mobility foundation model with corner case data at scale is becoming a reality through our approach. We are working to further increase the information density of the simulated scenarios through ML-guided hard scenario generation. This helps discover interesting corner cases more efficiently. We are also working on expanding the coverage of the simulation to multiple operational domains.
Join our team!
We are hiring engineers to help scale up our data, GPU and simulation infrastructure. If you are interested in joining our team, please reach out to us!

